



Predictive data analytics is an important industry application of machine learning. Implementing predictive data analytics solutions involves more than just selecting the appropriate machine learning algorithm.
What is Predictive Data Analytics
Predictive data analytics involves the creation and application of models for making predictions based on patterns identified in historical data. These models are often trained using machine learning techniques.
In daily life, we often guess what will happen next. But in data analytics, 'predicting' can mean different things. Sometimes it's about guessing future prices. Other times, it's about figuring out what category something belongs to, like what kind of document we have.
Predictive Data Analytics for Price Prediction
Hotel chains, airlines, and online retailers must continually modify their pricing strategies to optimize revenue. This adjustment is influenced by various elements, including seasonal variations, changes in consumer demand, and the presence of special events.
Businesses can use predictive analytics models, which are trained using historical sales data, to forecast the most effective prices. These predicted prices can then guide their pricing strategy decisions.
Predictive Data Analytics for Propensity Modeling
Propensity modeling involves predicting the probability of individual customers engaging in specific behaviors.
These behaviors can include purchasing various products, reacting to certain marketing initiatives, or switching from one mobile phone operator to another.
Predictive Data Analytics for Dosage Prediction
Doctors and scientists often determine the appropriate amount of medication or chemicals to use in treatments.
Predictive analytics models can assist in predicting the optimal dosages by analyzing historical data on past dosages and their corresponding outcomes.
Predictive Data Analytics for Diagnosis
Doctors, engineers, and scientists typically rely on their extensive training, expertise, and experience to make diagnoses.
Predictive analytics models, however, utilize vast datasets of historical examples, encompassing a scale far greater than what an individual might encounter throughout their career.
The insights derived from predictive analytics can aid these professionals in making more accurate and informed diagnoses.
Predictive Data Analytics for Risk Assessment
Risk plays a crucial role in decision-making processes like loan issuance or insurance policy underwriting.
Predictive analytics models, once trained on historical data, can identify key risk indicators.
The insights gained from these models can be employed to make more informed and accurate risk assessments.
Predictive Data Analytics for Document Classification
Predictive data analytics has the capability to automatically categorize various types of documents, including images, sounds, and videos, into distinct categories.
This functionality is useful in a range of applications such as assisting in medical decision-making processes, directing customer complaints to the appropriate channels, or filtering email spam.
Predictive Data Analytics Project Lifecycle
The likelihood of success in a predictive data analytics project is heavily reliant on the process employed to manage the project. Therefore, it is advisable to focus on and utilize a well-defined project management process for these initiatives.
In predictive data analytics projects, the majority of the work, approximately 80%, is concentrated in the phases of Business Understanding, Data Understanding, and Data Preparation.
Conversely, only about 20% of the effort is dedicated to the Modeling, Evaluation, and Deployment phases.
In predictive data analytics projects, some phases are more closely interconnected. For instance, the Business Understanding and Data Understanding phases are tightly coupled, often leading to projects oscillating between these two stages.
Likewise, the Data Preparation and Modeling phases are closely connected, with projects frequently alternating between these phases.
Business Understanding
Predictive data analytics projects typically begin with objectives such as acquiring new customers, increasing product sales, or enhancing process efficiencies.
The process of developing a predictive model should start with a deep understanding of the business problem, ensuring that the model not only predicts accurately but also provides actionable and relevant insights for the business.
In the initial phase, the primary responsibility of the data analyst is to comprehensively understand the business or organizational problem at hand. Following this understanding, the next step involves designing a data analytics solution to tackle this problem.
Data Understanding
At this stage, the data analyst gains a thorough understanding of the available data sources within the organization and the types of data these sources contain.
For building predictive data analytics models, it's crucial to have specific types of data, which need to be organized in a particular structure known as an Analytics Base Table (ABT).
This structured approach is essential for effective model development.
Data Preparation
This phase encompasses all the necessary activities to transform the various data sources within an organization into a well-structured ABT.
The ABT is the key element from which machine learning models can be effectively trained, ensuring that the data is in a format suitable for this purpose.
Modeling
During the Modeling phase, the focus shifts to the actual machine learning work.
This involves employing different machine learning algorithms to construct a variety of predictive models.
From this range, the most effective model is identified and selected for deployment.
This phase is crucial for determining the most suitable model based on performance and applicability to the specific problem.
Evaluation (Testing)
Prior to deploying models within an organization, it is vital to thoroughly evaluate them to ensure they are suitable for the intended purpose.
The evaluation phase encompasses all tasks necessary to demonstrate that a prediction model is capable of making accurate predictions once deployed.
This includes verifying that the model does not suffer from overfitting or underfitting, which are critical factors for its effectiveness and reliability in practical applications.
Deployment
The final phase of a machine learning project involves all the work necessary to successfully integrate a machine learning model into an organization's existing processes.
This phase is critical, as it ensures that the developed model effectively serves its intended purpose.
It covers aspects such as deploying the model into a production environment, integrating it with existing systems, and ensuring it operates seamlessly within the organization's processes.
Predictive Data Analytics Tools
The initial decision in selecting a machine learning platform involves choosing between an application-based solution and a programming language-based approach.
Application-based Solutions for Building Predictive Data Analytics Models
Application-based, or point-and-click, tools are well-designed to facilitate the rapid and straightforward development, evaluation of models, and execution of associated data manipulation tasks. Utilizing such tools, one can train, evaluate, and deploy a predictive data analytics model in a remarkably short time, potentially in less than an hour.
Enterprise-wide solutions
Key application-based solutions for constructing predictive data analytics models include platforms like IBM SPSS, Knime Analytics Platform, RapidMiner Studio, SAS Enterprise Miner, and Weka. These tools offer user-friendly interfaces and a range of functionalities that streamline the model development process, making them especially valuable for users who may not have extensive programming expertise.
The tools offered by IBM and SAS are designed as enterprise-wide solutions, seamlessly integrating with other products and services provided by these companies. This integration facilitates a cohesive and comprehensive approach to data analytics within larger organizations.
Open-source solutions
In contrast, Knime, RapidMiner, and Weka stand out for being open-source and freely available. These tools provide a significant advantage for individuals or organizations looking to explore predictive data analytics without an initial financial commitment.
The open-source nature of these platforms also encourages a community-driven approach to development and problem-solving, offering a wealth of resources and support for users at all levels of expertise.
Programming languages for Building Predictive Data Analytics Models
R and Python are indeed two of the most widely used programming languages in the field of predictive data analytics.
Building predictive data analytics models using languages like R or Python is not overly challenging, particularly for those who have some background in programming or data science.
Advantages
One of the significant advantages of using a programming language is the immense flexibility it provides to data analysts. Virtually anything that the analyst can conceptualize can be implemented.
In contrast, application-based solutions have limitations in terms of flexibility. Analysts using these tools can typically only achieve what the developers had in mind when designing the tool.
Additionally, the most recent advanced analytics techniques are accessible in programming languages well before they are incorporated into application-based solutions
Disadvantages
Certainly, using programming languages does come with its drawbacks. The primary disadvantage is that programming is a skill that requires a significant investment of time and effort to learn.
Utilizing a programming language for advanced analytics presents a notably steeper learning curve compared to using an application-based solution.
The second drawback is that when using a programming language, there is generally limited infrastructural support, including data management, which is readily provided by application-based solutions. This places an additional responsibility on developers to implement these essential components themselves.
Supervised machine learning
To build the models for predictive data analytics applications, supervised machine learning is often used. It starts with a collection of data that has already been labeled with the correct answer. The dataset is referred to as a labeled dataset if it includes values for the target feature.
Other types of machine learning include unsupervised learning, semi-supervised learning, and reinforcement learning.
Historical Dataset to Train a Model
A machine learning algorithm analyzes the training dataset and develops a model by finding patterns between the descriptive features and the target feature based on a set of historical examples (training dataset), or historical instances.
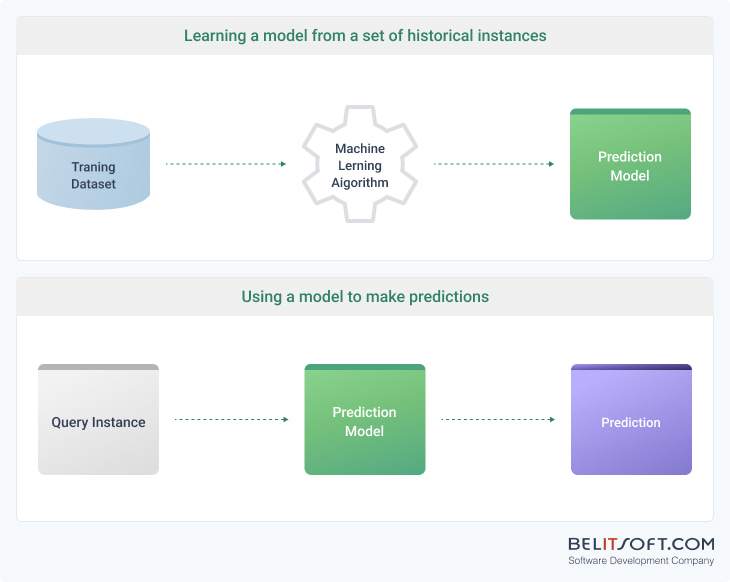
The model's goal is to understand the relationships in such a way that it can predict the target feature for new, unseen instances.
Descriptive features and a Target feature
In supervised learning, the target feature is known from the training (historical) dataset.
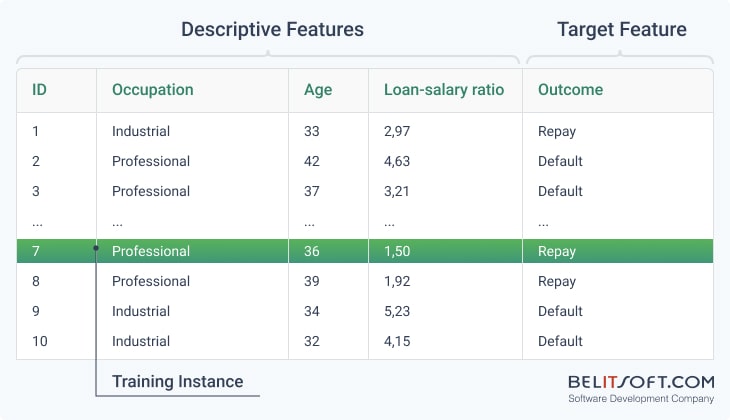
It's used to train a machine learning model to predict the probability that a mortgage applicant will fail to repay the loan as agreed (credit default risk).
In this dataset, the descriptive features are occupation, age and loan-salary ratio of the loan amount to the applicant's salary.
The "Outcome" field (a target feature) indicates whether the mortgage applicant has failed to make the payments on their loan according to the agreed terms, an event which is recorded as "default".
Model consistency with the dataset
A model that is consistent with the dataset is one that accurately reflects the relationships between the features and the target outcome in the historical data. Consistency means that for every instance where the model makes a prediction, the prediction matches the actual outcome that is recorded in the historical dataset.
For instance, if the model predicts that a person with a certain age, occupation, and loan-salary ratio will default on a loan, and the dataset shows that the person did indeed default, then the model's prediction for that instance is consistent with the dataset.
A consistent model not only fits the training data but also generalizes well to unseen data. Such model's predictions are stable across the dataset even if there are small variations in the input data.
Machine learning is not for simple datasets
For simple datasets with 3 descriptive features and dozens of instances, we can manually create a prediction model.

A decision rule model used to predict loan repayment outcomes in this case:
- If the ratio of the loan amount to the borrower's salary is greater than 3.1, then the prediction is that the borrower will default on the loan.
- If the loan-to-salary ratio is not greater than 3.1, then the prediction is that the borrower will repay the loan.
However, to manually learn the model by examining the large datasets containing thousands or even millions of instances, each with multiple features is almost impossible.
The simple prediction model using only the loan-salary ratio feature is no longer consistent with more complex datasets.
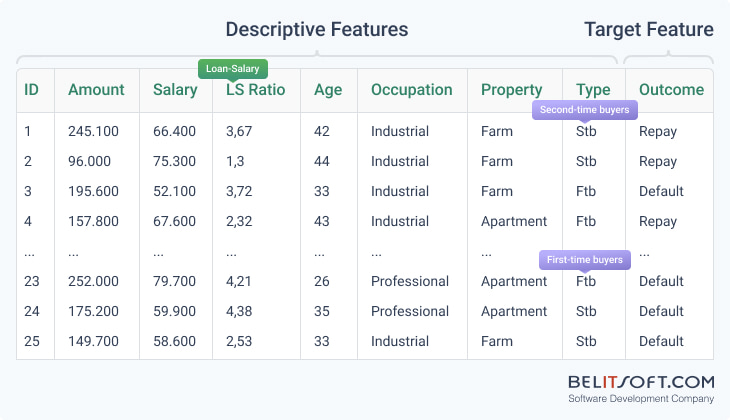
A training historical credit scoring dataset with 25 historical instances, 7 descriptive features and 1 target feature (outcome). FYI: Ftb are first-time buyers, stb are second-time buyers.
A decision rule model used to predict loan repayment outcomes in this case:
- If the borrower's loan amount is less than 1.4 times their salary, then predict that the borrower will repay the loan.
- If the loan amount is more than 4.1 times the borrower's salary, then predict that the borrower will default on the loan.
- If none of the above conditions are met, but the borrower is younger than 39 years old and works in the industrial sector, then predict that the borrower will default on the loan.
- If none of the above conditions are met, predict that the borrower will repay the loan.

When we want to build consistent prediction models from large datasets with multiple features, machine learning is the solution. It’s able to detect relations which are not immediately obvious and could be missed in a manual examination of the data.
Machine learning algorithms notice "unnoticed" patterns
Detecting such relations manually is very difficult, especially when there are many features. As you add more features, the number of possible combinations increases exponentially, making it virtually impossible to manually explore all potential rules.
A simple observation might suggest that a high 'Loan-Salary Ratio' leads to a higher likelihood of default. However, there might be an interaction between 'Loan-Salary Ratio' and 'Occupation'. For instance, it could be that professionals with a high loan-salary ratio default less often than industrial workers with a high loan-salary ratio because they have more stable incomes or better prospects for salary increases.
Patterns that are subtle may only emerge when looking at the data in aggregate, often through statistical methods.
A statistical analysis may reveal, for example, that defaults are more common among industrial workers who are younger than 40 and have a loan-salary ratio greater than 3. This pattern might not be obvious when looking at individual records because it's the combination of three separate features.
There could also be a threshold effect where defaults spike once the loan-salary ratio exceeds a certain value, but below that threshold, the ratio has little impact on the likelihood of default. Without statistical analysis, such threshold effects could go unnoticed.

Rate this article
Recommended posts
.jpg)
.jpg)
.jpg)
.jpg)

.jpg)
.jpg)
.jpg)
.jpg)
Portfolio

Our Clients' Feedback












They use their knowledge and skills to program the product, and then completed a series of quality assurance tests. We were working in an agile way with them. Belitsoft performed very well throughout our project. We are definitely looking at Belitsoft as a long-term partner.

Service Delivery Director at Crimson (United Kingdom)
I highly recommend Belitsoft for website design and development. We were up against a tight deadline to launch the project. The work was delivered on time and within budget! I will continue working with Belitsoft as a valued partner for our web development!

Program Administrator at UC Berkeley (United States)
We have worked with Belitsoft team over the past few years on projects involving much customized programming work. They are knowledgeable and are able to complete tasks on schedule, meeting our technical requirements. We would recommend them to anyone who is in need of custom programming work.

Main Partner at Hathway Tech (United States)
Belitsoft company is able to make changes instantly. One of our internal engineers has commented about how clean their code is. Belitsoft seems to know what they're doing, which I appreciate.

Co-Founder at HOWCAST MEDIA (United States)
It was a great pleasure working with Belitsoft software development company. New requirements and adjustments were implemented fast and precisely. We can recommend Belitsoft and are looking forward to start a follow-up project.

Head of Division at Fraunhofer FIT (Germany)
Belitsoft company has been able to provide senior developers with the skills to support back end, native mobile and web applications. We continue today to augment our existing staff with great developers from Belitsoft.

CEO at Apollo Matrix (United States)
Belitsoft company delivered dedicated development team for our products, and technical specialists for our clients' custom development needs. We highly recommend to use this company if you want the same benefits.

Managing Director at Key2Know A/S in 2012 (Denmark)
We approached BelITsoft with a concept, and they were able to convert it into a multi-platform software solution. Their team members are skilled, agile and attached to their work, all of which paid dividends as our software grew in complexity.

COO at Regenerative Medicine LLC (United States)
Having worked with Belitsoft as a service provider, I must say that I'm very pleased with the company's policy. Belitsoft guarantees first-class service through efficient management, great expertise, and a systematic approach to business. I would strongly recommend Belitsoft's services to anyone wanting to get the right IT products in the right place at the right time.

CEO at Moblers (Israel)
If you are looking for a true partnership Belitsoft company might be the best choice for you. They have proven to be most reliable, polite and professional. The team managed to adapt to changing requirements and to provide me with best solutions. I strongly recommend Belisoft.

Director at ShowCast Limited (Germany)
I expected and demanded a lot of you at Belitsoft company, but you exceeded my expectations. You acted pro-actively, challenged me at the right moments. Thanks!"

CEO at Ticken B.V. (Netherlands)
We have been working for over 10 years and they have become our long-term technology partner. Any software development, programming, or design needs we have had, Belitsoft company has always been able to handle this for us.

СEO at ElearningForce International (United States/Denmark)
Belitsoft has been the driving force behind several of our software development projects within the last few years. This company demonstrates high professionalism in their work approach. They have continuously proved to be ready to go the extra mile. We are very happy with Belitsoft, and in a position to strongly recommend them for software development and support as a most reliable and fully transparent partner focused on long term business relationships.
Global Head of Commercial Development L&D at Technicolor